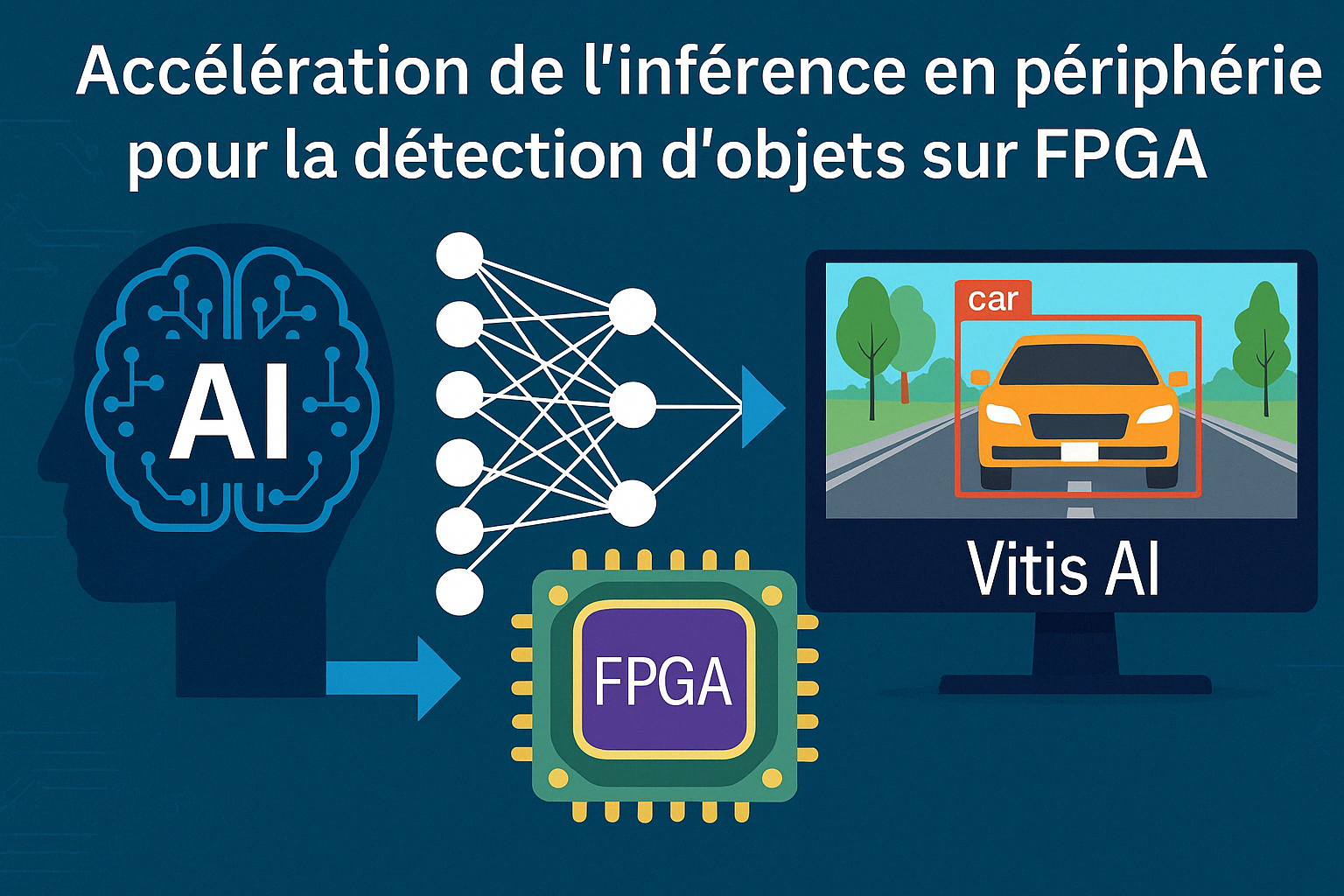
Accélération de l’inférence en périphérie pour la détection d’objets sur FPGA
Contexte :
L’intelligence artificielle embarquée connaît une croissance rapide dans des domaines tels que la surveillance, la robotique, la ville intelligente ou les véhicules autonomes. Ces applications exigent des modèles de détection d’objets rapides, efficaces et déployables en périphérie (edge computing), où les ressources sont limitées en puissance de calcul et en énergie.
Problématique :
Les processeurs classiques (CPU) et les cartes graphiques (GPU) offrent de bonnes performances d’inférence, mais au prix d’une consommation énergétique élevée. Ils ne sont donc pas toujours adaptés pour des déploiements embarqués en temps réel.
Comment peut-on atteindre un compromis optimal entre performance d’inférence, faible consommation énergétique et compatibilité embarquée ?
Objectifs :
- Optimisation du modèle de détection d’objet Yolov5 ;
- Réduction de la latence tout en maintenant une précision acceptable ;
- Déploiement du modèle quantifié sur une architecture matérielle optimisée (FPGA) ;
- Validation des performances par application en temps réel.
Méthodologie :
La méthodologie s’est d’abord appuyée sur l’analyse de différents modèles de détection d’objets, menant au choix de YOLOv5 pour ses performances en temps réel. Des techniques comme la quantification et l’élagage ont ensuite été étudiées pour adapter le modèle à une implémentation sur FPGA. L’outil Vitis AI de Xilinx a été utilisé pour compiler et déployer le modèle sur la carte Kria KV260. Un script d’inférence en C++ a été développé pour exécuter le modèle quantifié directement sur le matériel. Finalement, des tests sur images et vidéos simulées ont permis d’évaluer les performances du système en conditions proches du réel.
Résultats :
-
Excellente efficacité énergétique : La Kria KV260 consomme seulement 1,213 W, contre 42,61 W pour une carte GPU, pour des performances proches.
-
Cadence d’inférence élevée : Le FPGA atteint 65 FPS sur une base de données d’images, mieux que le CPU (60 FPS), et 142 FPS lors d’une execution temps réel avec une bien meilleure efficacité énergétique.
-
Latence compétitive : Temps d’exécution de 16 ms, comparable à celui du CPU (15,9 ms), mais avec bien moins de consommation.
-
Quantification optimisée : Le passage à 8 bits permet une exécution rapide et une réduction de l’usage des ressources matérielles.
-
Mémoire bien exploitée : Des taux de lecture/écriture optimaux (jusqu’à 1 GB/s en lecture) et aucun goulot d’étranglement détecté.
Conclusion :
Le FPGA, grâce à sa flexibilité et sa capacité de parallélisation, permet un déploiement IA efficace en périphérie. Il constitue une solution prometteuse pour les systèmes embarqués.
Perspectives :
-
-
Optimisations supplémentaires (fusion de couches, noyaux personnalisés).
-
Support de modèles plus complexes.
-
Intégration dans des systèmes industriels réels.
- Développement d’une architecture hardware (Image Linux ) pour plus de flexibilité.
-
Présenté par
Achraf Chakroun, étudiant à la maîtrise en ingénierie