Développement d’un système de prédiagnostic médical : la prédiction des codes ICD-10
- Contexte : Le codage médical ICD-10 est souvent long et sujet à des erreurs, surtout avec de grandes quantités de données. Les approches classiques s’appuient majoritairement sur le texte, ce qui limite la fiabilité. D’où l’intérêt de développer des solutions basées sur des données numériques.
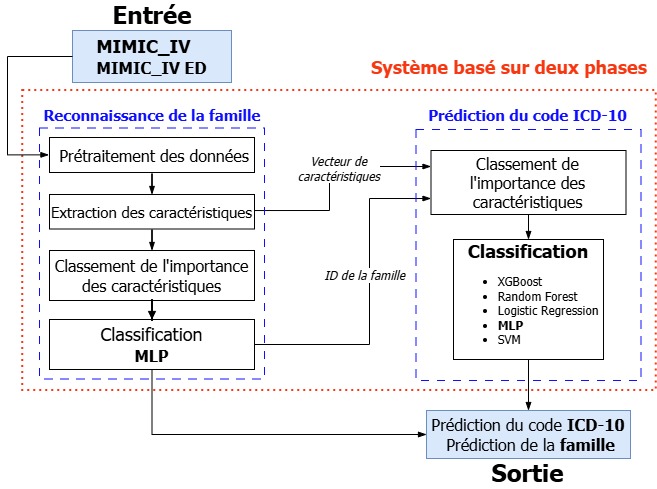
- Objectif : Créer un système automatique de prédiction des codes ICD-10 en deux étapes, en utilisant uniquement des données numériques pour améliorer la précision et réduire les erreurs humaines.
- Méthodologie :
-
Utilisation des bases de données MIMIC-IV et MIMIC-IV-ED.
-
Prétraitement des données : nettoyage, normalisation et sélection.
-
Extraction des caractéristiques
-
Sélection des variables les plus pertinentes.
-
Phase 1 : Classification de la famille pathologique via un MLP.
-
Phase 2 : Prédiction du code ICD-10 spécifique avec divers modèles (XGBoost, Random Forest, etc.).
-
Évaluation avec des métriques de classification (Exactitude, Précision, Rappel, AUC).
-
- Résultats : Les modèles testés ont obtenu de très bons scores, notamment en exactitude et en AUC. Le système hiérarchique a montré une amélioration claire des performances globales.
- Conclusion : L’approche fondée sur les données numériques et la structure hiérarchique a permis une prédiction efficace et standardisée. Une extension future pourrait intégrer les données textuelles pour encore plus de précision.
Présenté par
Rihab Baccari, étudiante à la maîtrise en informatique
Partenaires