Système automatisé d’extraction de données semi-structurées pour PDF
Les documents PDF représentent un moyen courant de partage d’information et ils sont utilisés par de nombreux organismes
et entreprises de toutes sortes. Il existe deux catégories d’information que peut transmettre un document PDF. Une de ces catégories est une information qualifiée de semi-structurée et est représentée à travers l’utilisation de tableaux de données.
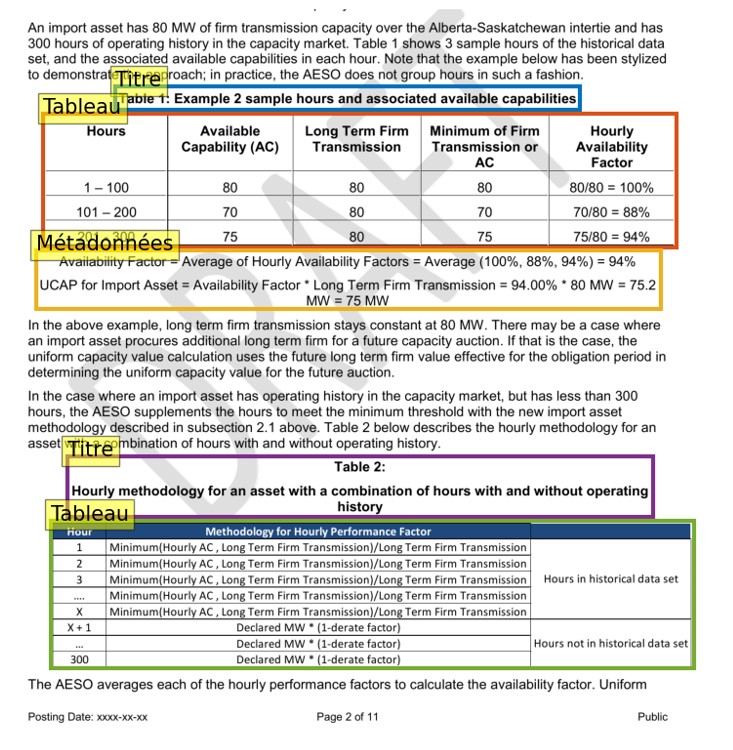
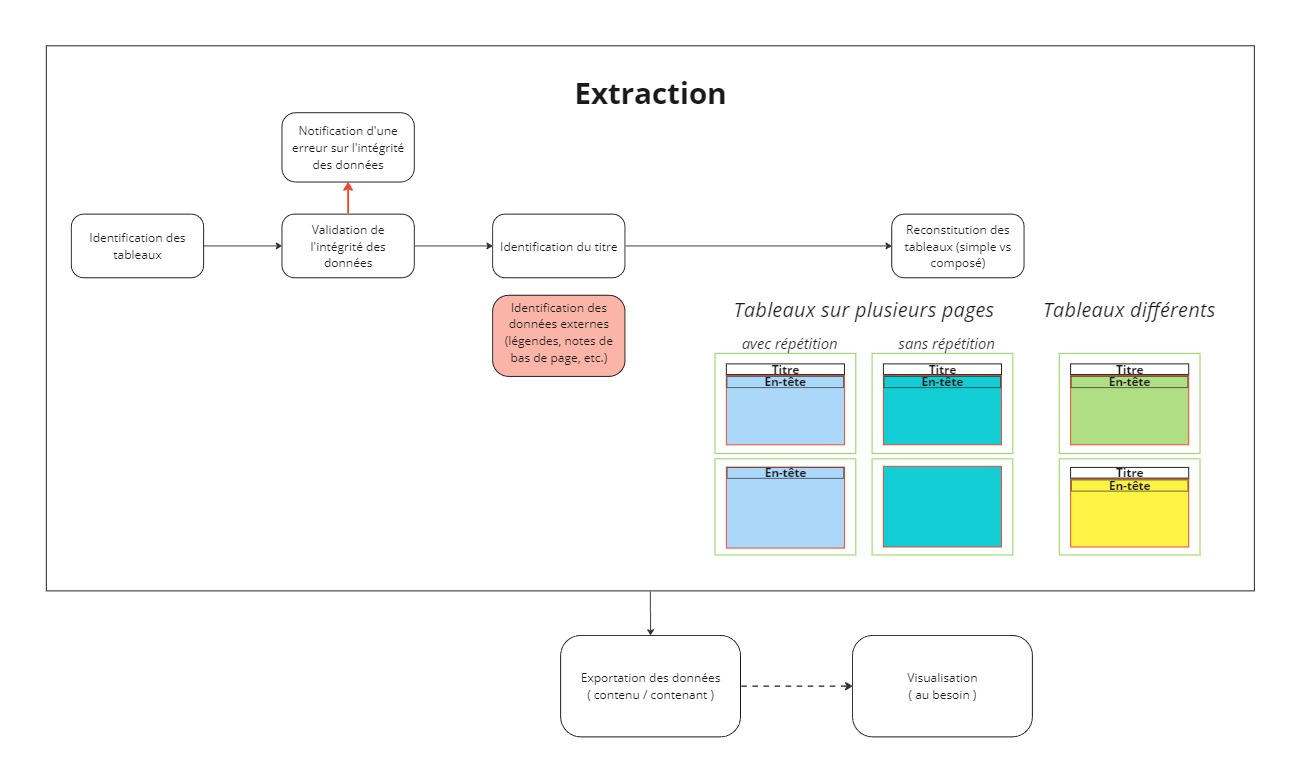
Dans le cadre de notre projet, le mandat était de développer un système permettant la récupération automatique d’information semi-structurée, présente au sein des différents tableaux des documents PDF.[1]
Présenté par
- Frédérik Boutin & Gabriel Létourneau, étudiants au baccalauréat en informatique
- Yacine Benahmed, professeur